- 国内业务:16675576380
2025-02-24
ChatGPT之所以如此好,是因为它经历了多个关键的改进。大型语言模型(LLM)现在能够遵循人类指令并提供有用的回应,而不仅仅是预测下一个词。这是通过使用专门的指令数据集和人类反馈强化学习(RLHF)技术对模型进行微调实现的。
过去一年里,LLM的应用范围发生了巨大变化。像OpenAI的GPT-3和ChatGPT以及其他强大的语言模型,如DeepMind的Sparrow和Anthropic的Claude,能够执行各种任务,从写结婚致辞、投诉邮件到科学文章总结和代码调试等。这些模型不仅功能强大,而且富有趣味性,超出了最初研究人员和从业者对原始GPT-3的期望。开发者和公司开始将这些LLM应用于几乎任何语言任务,从法律发现到医疗建议。
GPT-3及其相关模型的进步得益于Transformer架构的引入。该架构在语言任务上比以前的模型效果提高了几个数量级。这些模型具备出色的文本生成、摘要和自动完成能力。它们还具备广博的“世界知识”并在“上下文学习”方面非常有效,能够生成以前未见过的测试用例的解决方案。然而,在生成连贯的文本方面,这些模型需要相对高级的提示,并且在执行任务或遵循人工指令时(如“编写故事”或“调试此代码”),遇到困难并容易出错。
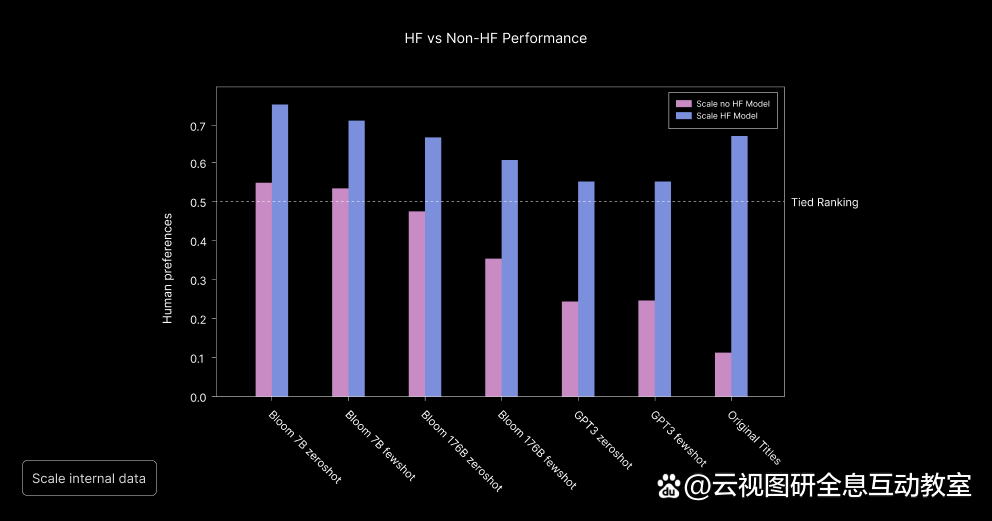
y 轴上的人类偏好分数衡量 x 轴上各个模型对人类评价的响应。每个模型都有一个人类偏好分数,用于根据人类反馈数据和没有人类反馈数据进行微调的变体。资料来源:规模人工智能
通过微调LLM的模型,如ChatGPT,这些问题得到了改善。与原始的GPT-3相比,ChatGPT在生成连贯、冗长的回答方面表现出色,并更好地理解上下文和指令。微调的模型能够提供符合人类价值观的回答,并且在解决各种任务时表现出更好的性能。
为了进一步改善LLM的表现,引入了人类反馈强化学习(RLHF)。这种方法训练了一个额外的奖励模型,从人类的角度评估LLM的回应质量,并指导LLM的学习过程。通过RLHF,模型能够提供更长、更合适的回答,并拒绝不适当或模型知识范围之外的问题。此外,RLHF还使得LLM在实际对话中能够参与上下文中介绍了如何实施RLHF。首先,收集人类演示数据,通过给定的提示要求人类注释者提供适当的回答,并使用这些数据对语言模型进行微调。其次,生成输出并收集比较数据,以训练奖励模型。比较数据通过人工注释对不同模型生成的回答进行排名,用于训练奖励模型评估回答的质量。最后,通过结合微调模型输出和奖励模型,进行强化学习,不断改进模型的表现。
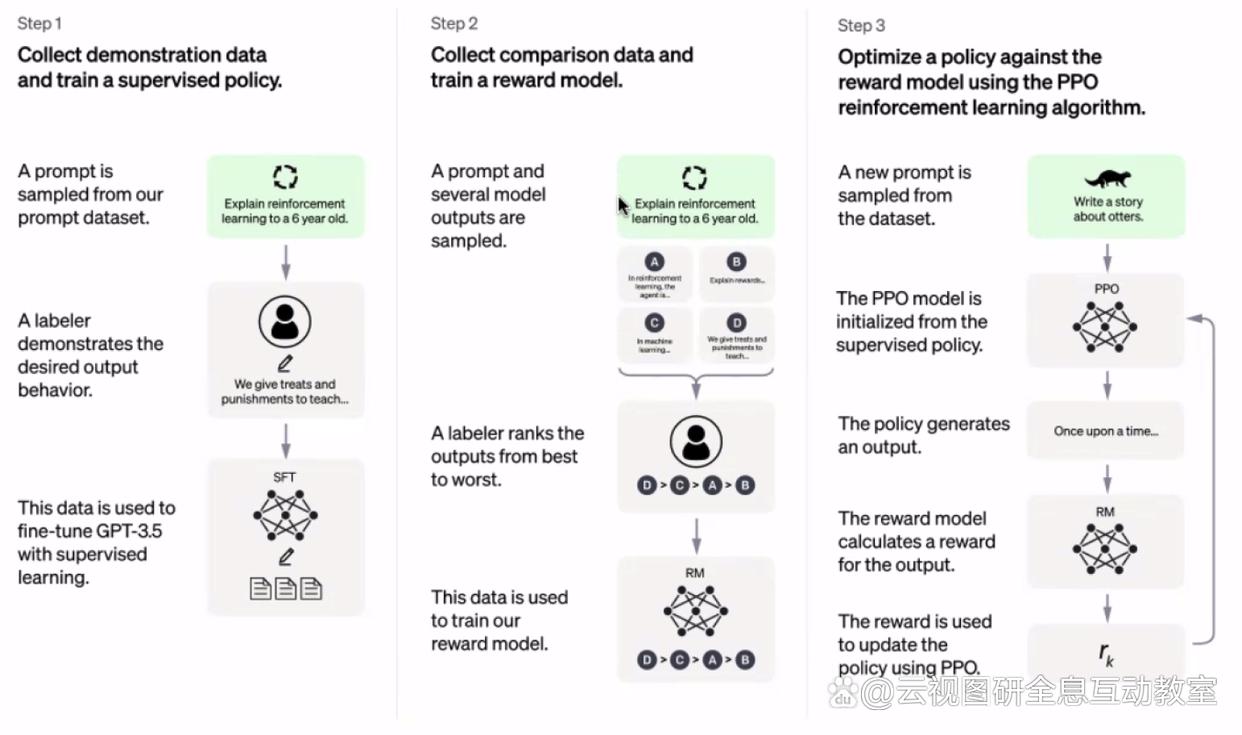
图来自 OpenAI 的论文“Training language models to follow instructions with human feedback”
对于那些无法访问LLM权重进行微调的情况,也提供了一些替代方案。其中一种是训练自己的语言模型或使用开源的LLM,虽然这需要一定的成本和精力。另一种是使用奖励模型对LLM的调用进行拒绝抽样,以确保生成的回答符合人类价值观。还有一种方法是直接对LLM进行微调,使用在步骤2中收集的比较数据,这可以改善LLM在实践中的表现。
ChatGPT之所以如此好,得益于微调和人类反馈强化学习的应用。通过这些技术,ChatGPT能够生成更有用、符合人类价值观的回答,并在各种任务中表现出更好的性能。这些进展使得大型语言模型在解决实际问题和应用中具有更大的潜力。

